Update November 2019:
Das Twitter-Archiv wird nicht mehr als CSV-Datei ausgegeben, daher ist diese Anleitung veraltet! Wenn du noch ein Archiv mit einer tweets.csv hast, kannst du diese Anleitung verwenden.
Ich bin schon lange auf Twitter. Um genau zu sein seit dem 3.3.2009. In diesen (bald) 9 Jahren haben sich einige viele Tweets angesammelt. Unter all den Mentions, Bildern und Retweets stecken auch so manche Erinnerungen oder Top-Tweets, die man gerne wieder anschauen möchte. Man könnte zwar die Timeline durchgehen, um die betreffenden Tweets zu sehen, aber bei vielen tausend Tweets (ich bin – Stand Januar 2018 – bei 192 100 Tweets) ist das unmöglich.
Zum Glück kann man mittlerweile direkt bei Twitter sein eigenes Twitter-Archiv herunterladen und einsehen. Man bekommt eine zip-Datei mit all seiner Tweets und kann diese im Browser direkt ansehen oder nach bestimmten Phrasen durchsuchen. Das Twitter-Archiv kann außerdem auf einen Webspace geladen werden, sodass ihr es euch dort ansehen könnt. Naturlich nur die öffentlichen Tweets, die DMs bekommt keiner zu Gesicht!
Leider brauchen viele Browser recht lange bei der Größe meines Archivs, um Suchergebnisse darstellen zu können. Ist das ganze Twitter-Archiv auf einem Webserver gehostet, dauert das ganze unter Umständen noch länger. Um nicht ewig auf eine Antwort des Browser zu warten, habe ich mir gedacht, dass es doch eine einfachere Lösung geben müsste.
(Diejenigen, die den folgenden technischen Schurz nicht lesen wollen, können einfach hier zum Eingemachten springen.)
Das Twitter-Archiv liegt neben den monatlichen json-Dateien auch in einer csv-Datei bei (die bei mir mittlerweile 43 MB umfasst). Das ist ein datenbank-ähnliches Dateiformat, mit dem man strukturiert Daten speichern kann. Stellt euch dazu einfach eine einzige Tabelle vor, die alle eure Tweets und deren Informationen wie Sender, Zeitpunkt, Text usw beinhaltet. In dieser könnt ihr mittels Suchfunktion die betreffenden Stellen herausfinden.
In unserer informationstechnischen Welt können Datenbanken nicht mehr weggedacht werden. Irgendwo muss man die Daten schließlich speichern können. Über die vergangenen Jahre haben sich unterschiedliche Datenbanken herauskristallisiert. Bekannteste Beispiele sind relationale Datenbanken wie MySQL oder SQLite. In diesen werden die Daten in Tabellen gespeichert, welche wiederum untereinander verknüpft werden können. (Auf NoSQL-Datenbanken möchte ich nicht weiter eingehen, das würde den Rahmen sprengen.) Um diese Datenbanken anzusprechen, wurde eine Programmiersprache entwickelt, welche sich SQL schimpft. Okay, schimpfen ist zu böse, ohne sie sähen wir ziemlich alt aus… Im späteren Verlauf werden wir uns dieser auch bedienen. Natürlich nur in einem kleinen Rahmen.
Zurück zu meiner Idee mit dem Twitter-Archiv: da die csv-Datei recht unkomfortabel zu durchsuchen ist, wollte ich diese in eine MySQL-Datenbank stecken. Das hat den Vorteil, dass ich die resultierende Tabelle recht fix und einfach mit SQL-Befehlen durchsuchen lassen kann. Außerdem werden die Ergebnisse schneller angezeigt, als wenn ich auf den Browser warten muss. Der Import der Datei in die Datenbank gestaltete sich erstmal sehr schwierig, da in der heutigen Zeit auch Emojis in Twitter gespeichert werden und es für mich sehr nervig war, diese in meine MySQL-Datenbank zu bekommen. Aber dank des Tipps von @Bardnet (Danke nochmal an der Stelle!) war es ein leichtes. Da viele von euch Twitteranern (Techies ausgenommen 😉 ) sicher keine eigene MySQL-Datenbank oder ähnliches benutzen, hier eine kleine Abhilfe, mit der ihr euer Twitter-Archiv auch in einer Datenbank speichern und durchsuchen könnt. Alles, ohne ein Programm zu installieren.
Diese Anleitung ist für Windows gedacht. Für Linux (wer das verwendet, sollte eh das technische KnowHow für Datenbanken besitzen) und macOS könnte der Ablauf ähnlich sein. Alle Angaben ohne Gewähr!
Was ihr dazu braucht:
- Euer Twitter-Archiv
- Einen mysql-Server
- Einen Datenbanken-Editor
Um euch das ganze zu vereinfachen, habe ich die letzten beiden Punkte für euch schon vorgefertigt und unter diesem Download für euch bereitgestellt. Es umfasst eine abgespeckte Variante der MySQL-Dateien (mysql-5.7.17-win32) und einen Datenbanken-Editor (HeidiSQL 9.4). Ihr müsst dazu nichts installieren – nur die zip-Datei entpacken.
Twitter-Archiv
Ihr müsst erst unter https://twitter.com/settings/account und “Dein Twitter Archiv” euer Twitter-Archiv anfordern. Dieses erhaltet ihr dann per E-Mail. Die zip-Datei müsst ihr entpacken. Wir benötigen aus dem Paket die “tweets.csv”!
mysql-Server
Ihr geht nun in den Ordner “twarchivDB” (nicht das Twitter-Archiv – das Paket mit dem mysql-Server und dem Editor!) und dort in den Ordner “mysql”. Dort befinden sich drei .bat-Dateien. Das sind Batch-Dateien, die Befehle ausführen (wer sich sicher sein will, dass ich da keinen Schadcode eingepflanzt habe, der kann sie gerne öffnen). Ihr doppelklickt nun auf “initialize.bat” mit der ein paar Ordner und Konfigurationsdateien erstellt werden. Ist der Prozess beendet, wird euch gemeldet, dass ihr das Fenster nun schließen könnt.
Nun könnt ihr den MySQl-Server per “startServer.bat” starten. Schließt das Fenster jedoch nicht! Es könnte ein paar Warnungen geben, aber die dürft ihr ignorieren. Wenn die Meldung “mysql-server32\bin\mysqld: ready for connections.” auftaucht, dann ist der MySQL-Server bereit. Er wird voreingestellt auf dem Port 55555 laufen (der normal installierte Server würde auf 3306 laufen). Den Port könnt ihr in der Datei config.ini ändern – bevor der Server läuft.
Den Server beendet ihr über die Datei “stopServer.bat”. Das Fenster der Start-Datei sollte nach kurzer Zeit von selbst geschlossen werden.
Datenbank-Editor
Sofern noch nicht geschehen, entpackt ihr nun den Datenbank-Editor HeidiSQL. Im Ordner “HeidiSQL_9.5_Portable” findet ihr viele Dateien und auch eine “heidisql.exe”. Diese führt ihr nun aus (Doppelklick). Weiterhin könnt ihr die oben genannte tweets.csv (aus eurem Twitterarchiv) in den Ordner von HeidiSQL kopieren.
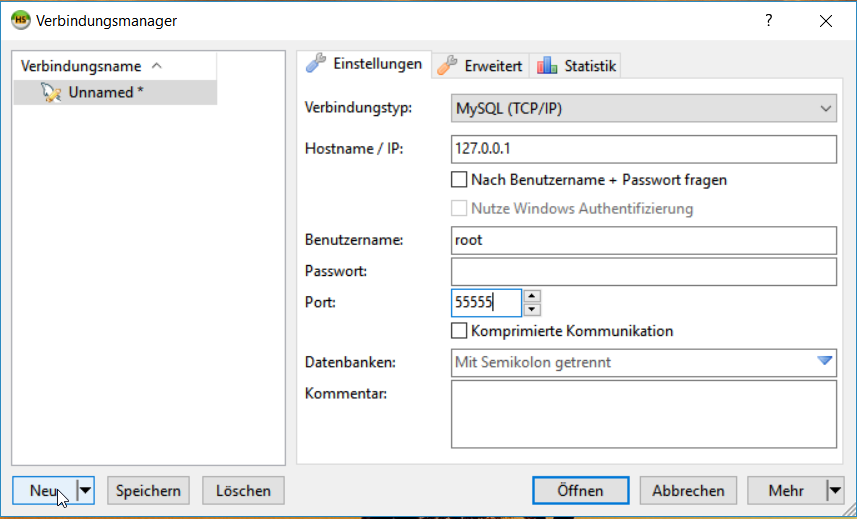
Beim ersten Start von HeidiSQL sollte sich ein Fenster namens Verbindungsmanager öffnen. Unten links klickt ihr auf “Neu” und auf der rechten Seite konfiguriert ihr die Datenbankverbindung. Wichtig ist hierbei, dass der Nutzername “root” ist (ohne Anführungszeichen), das Passwort leer bleibt, sowie der Port in 55555 geändert wird! Die IP sollte auch auf 127.0.0.1 stehen. Statt Unnamed könnt einen anderen Namen verwenden, wie “TAConnect”. Danach klickt ihr auf Öffnen und speichert eure Verbindung.
Es sollte sich HeidiSQL nun vollständig geöffnet haben. Auf der linken Seite seht ihr schon vorerstellte Datenbanken, welche aber für uns unwichtig sind.
Mittels Rechtsklick auf eine freie Fläche im linken Bereich könnt ihr eine neue Datenbank erstellen. Als Namen vergebt ihr einen passenden Datenbanknamen wie “twitterarchiv”. Die Kollation sollte unbedingt “utf8mb4_german2_ci” sein! Mit OK bestätigen.
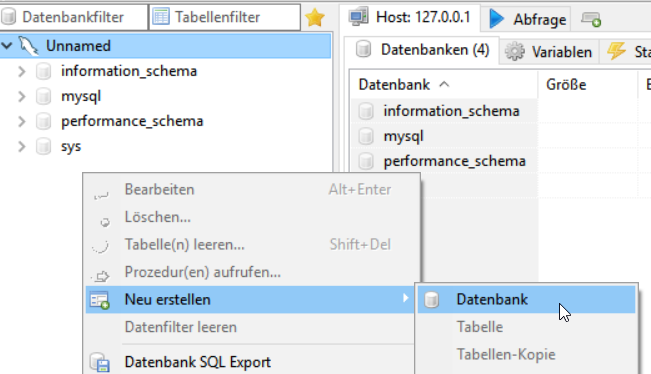
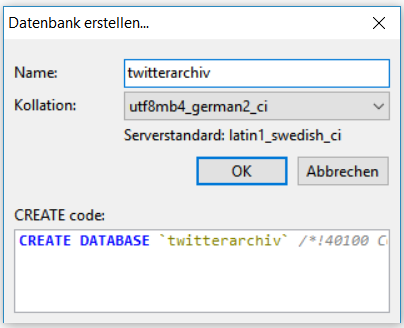
Importieren des Twitter-Archiv
Jetzt geht es ans Eingemachte! Geht nun auf die erstelle Datenbank und fügt auf der rechten Seite unter Abfrage den folgenden Code ein.
CREATE TABLE `tweets` (
`tweet_id` bigint(11) NOT NULL,
`in_reply_to_status_id` bigint(11) NOT NULL,
`in_reply_to_user_id` bigint(11) NOT NULL,
`timestamp` varchar(100) COLLATE utf8mb4_german2_ci NOT NULL,
`source` varchar(4000) COLLATE utf8mb4_german2_ci NOT NULL,
`text` varchar(4000) COLLATE utf8mb4_german2_ci DEFAULT NULL,
`retweeted_status_id` bigint(11) DEFAULT NULL,
`retweeted_status_user_id` bigint(11) DEFAULT NULL,
`retweeted_status_timestamp` bigint(11) DEFAULT NULL,
`expanded_urls` varchar(4000) COLLATE utf8mb4_german2_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_german2_ci;
LOAD DATA LOCAL INFILE 'tweets.csv' INTO TABLE tweets FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY '' LINES TERMINATED BY '\n';Habt ihr die tweets.csv in einem anderen Ort als dem Startort von HeidiSQL platziert (zB. auf eurer Partition C), dann müsste der Teil “C:\\tweets.csv” lauten. Klickt auf das blaue Dreieck in der Symbolleiste und lasst die Abfrage durchlaufen. Bei mir wurde am Ende eine Warnung ausgegeben, dass Werte nicht korrekt wären. Einfach mit Nein quittieren und gut ist. Die Tweets waren trotzdem da.
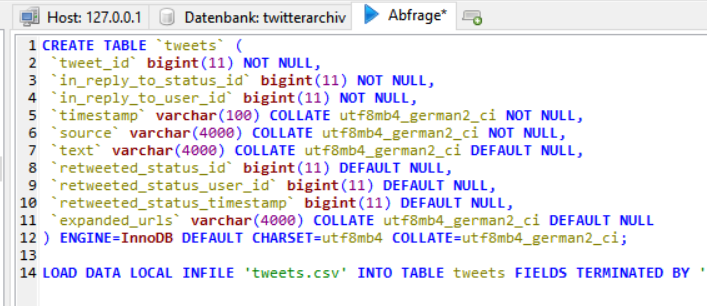
Danke an @Bardnet für das Snippet (welches ihr hier finden könnt)
SQL rulez!
Jetzt sind wir fertig und können unser Twitter-Archiv in der Datenbank ganz einfach befragen. Das läuft ganz easy über ein paar SQL-SELECT-Befehle ab, von denen ich euch nachfolgend ein paar Beispiele gebe. Versierte Nutzer können natürlich noch mehr damit machen.
Nutzernamen finden:
SELECT *
FROM tweets
WHERE text LIKE '%quantatheist%'
ORDER BY timestamp ASC;Text finden:
SELECT *
FROM tweets
WHERE text LIKE '%lustpolster%'
ORDER BY timestamp ASC;Tweets aus einem Zeitraum finden:
SELECT *
FROM tweets
WHERE (timestamp BETWEEN '2009-03-02' AND '2009-03-04')Ich hoffe, ich konnte euch somit ein wenig Zeit sparen, welche ihr beim Lesen dieses Artikels investiert habt. Viel Spaß mit eurem Twitter-Archiv. Bei Fragen oder Anregungen könnt ihr diese einfach in die Kommentare schreiben. Alle Angaben sind wie immer ohne Gewähr!